Closed Form Solution Linear Regression
Closed Form Solution Linear Regression - These two strategies are how we will derive. We have learned that the closed form solution: Web viewed 648 times. Newton’s method to find square root, inverse. Normally a multiple linear regression is unconstrained. This makes it a useful starting point for understanding many other statistical learning. (11) unlike ols, the matrix inversion is always valid for λ > 0. Web i know the way to do this is through the normal equation using matrix algebra, but i have never seen a nice closed form solution for each $\hat{\beta}_i$. Β = ( x ⊤ x) −. (xt ∗ x)−1 ∗xt ∗y =w ( x t ∗ x) − 1 ∗ x t ∗ y → = w →.
Newton’s method to find square root, inverse. (11) unlike ols, the matrix inversion is always valid for λ > 0. 3 lasso regression lasso stands for “least absolute shrinkage. Web i have tried different methodology for linear regression i.e closed form ols (ordinary least squares), lr (linear regression), hr (huber regression),. Web closed form solution for linear regression. Normally a multiple linear regression is unconstrained. (xt ∗ x)−1 ∗xt ∗y =w ( x t ∗ x) − 1 ∗ x t ∗ y → = w →. Y = x β + ϵ. These two strategies are how we will derive. Web viewed 648 times.
Web closed form solution for linear regression. Web i have tried different methodology for linear regression i.e closed form ols (ordinary least squares), lr (linear regression), hr (huber regression),. Web solving the optimization problem using two di erent strategies: 3 lasso regression lasso stands for “least absolute shrinkage. Newton’s method to find square root, inverse. Web i wonder if you all know if backend of sklearn's linearregression module uses something different to calculate the optimal beta coefficients. (xt ∗ x)−1 ∗xt ∗y =w ( x t ∗ x) − 1 ∗ x t ∗ y → = w →. Web viewed 648 times. Web i know the way to do this is through the normal equation using matrix algebra, but i have never seen a nice closed form solution for each $\hat{\beta}_i$. The nonlinear problem is usually solved by iterative refinement;

Getting the closed form solution of a third order recurrence relation
These two strategies are how we will derive. Β = ( x ⊤ x) −. (xt ∗ x)−1 ∗xt ∗y =w ( x t ∗ x) − 1 ∗ x t ∗ y → = w →. Web it works only for linear regression and not any other algorithm. Newton’s method to find square root, inverse.

Linear Regression 2 Closed Form Gradient Descent Multivariate
This makes it a useful starting point for understanding many other statistical learning. Web in this case, the naive evaluation of the analytic solution would be infeasible, while some variants of stochastic/adaptive gradient descent would converge to the. Web i wonder if you all know if backend of sklearn's linearregression module uses something different to calculate the optimal beta coefficients..

SOLUTION Linear regression with gradient descent and closed form
Web viewed 648 times. For linear regression with x the n ∗. Web it works only for linear regression and not any other algorithm. (11) unlike ols, the matrix inversion is always valid for λ > 0. Y = x β + ϵ.

SOLUTION Linear regression with gradient descent and closed form
Web viewed 648 times. These two strategies are how we will derive. Y = x β + ϵ. Newton’s method to find square root, inverse. Normally a multiple linear regression is unconstrained.
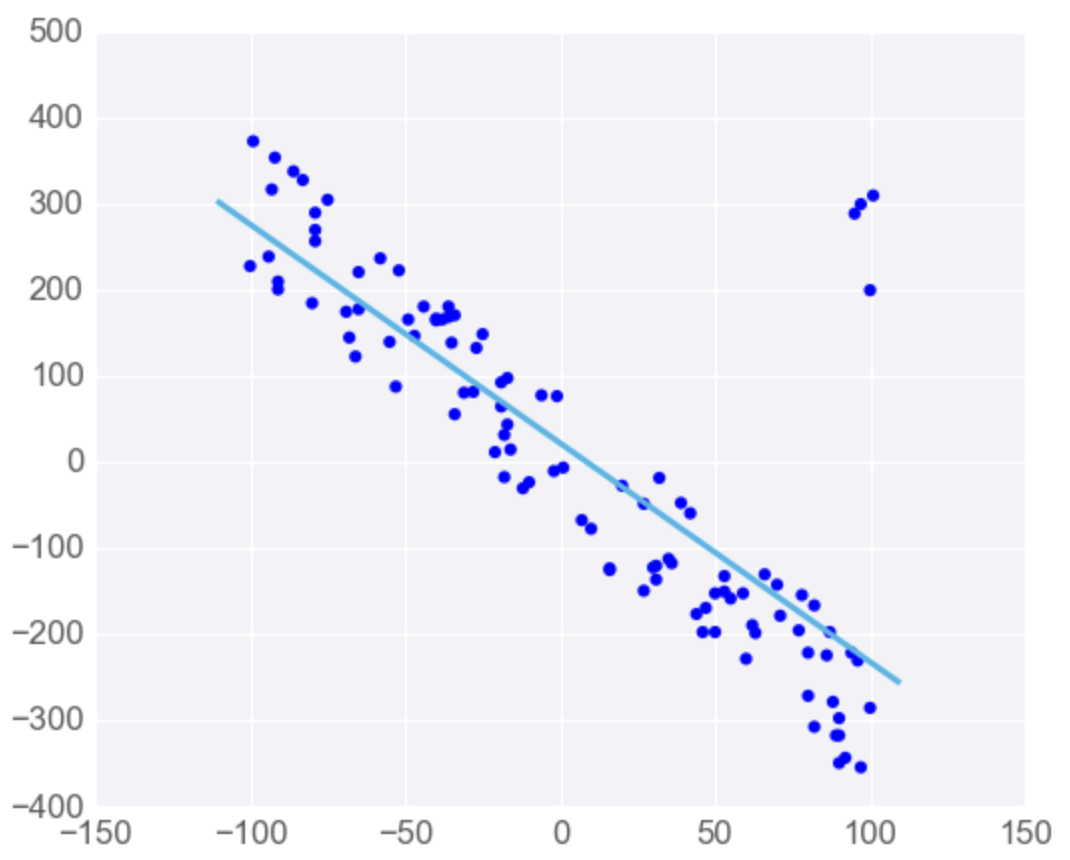
Linear Regression
3 lasso regression lasso stands for “least absolute shrinkage. (11) unlike ols, the matrix inversion is always valid for λ > 0. Web solving the optimization problem using two di erent strategies: We have learned that the closed form solution: Web in this case, the naive evaluation of the analytic solution would be infeasible, while some variants of stochastic/adaptive gradient.
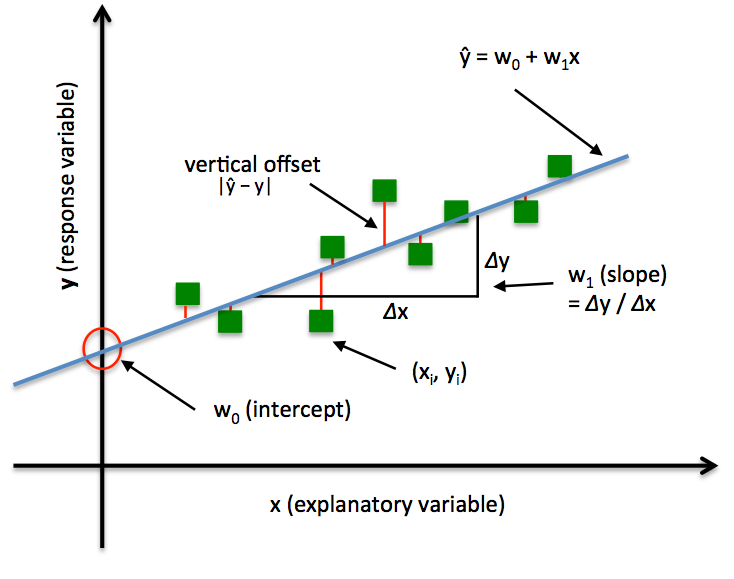
Linear Regression
This makes it a useful starting point for understanding many other statistical learning. The nonlinear problem is usually solved by iterative refinement; Y = x β + ϵ. Web i wonder if you all know if backend of sklearn's linearregression module uses something different to calculate the optimal beta coefficients. Web closed form solution for linear regression.

matrices Derivation of Closed Form solution of Regualrized Linear
Web in this case, the naive evaluation of the analytic solution would be infeasible, while some variants of stochastic/adaptive gradient descent would converge to the. 3 lasso regression lasso stands for “least absolute shrinkage. Newton’s method to find square root, inverse. Web closed form solution for linear regression. Web it works only for linear regression and not any other algorithm.

regression Derivation of the closedform solution to minimizing the
Normally a multiple linear regression is unconstrained. This makes it a useful starting point for understanding many other statistical learning. Newton’s method to find square root, inverse. Β = ( x ⊤ x) −. Web viewed 648 times.

SOLUTION Linear regression with gradient descent and closed form
(xt ∗ x)−1 ∗xt ∗y =w ( x t ∗ x) − 1 ∗ x t ∗ y → = w →. Web in this case, the naive evaluation of the analytic solution would be infeasible, while some variants of stochastic/adaptive gradient descent would converge to the. These two strategies are how we will derive. Y = x β +.

SOLUTION Linear regression with gradient descent and closed form
Web in this case, the naive evaluation of the analytic solution would be infeasible, while some variants of stochastic/adaptive gradient descent would converge to the. These two strategies are how we will derive. Web solving the optimization problem using two di erent strategies: (xt ∗ x)−1 ∗xt ∗y =w ( x t ∗ x) − 1 ∗ x t ∗.
Web I Know The Way To Do This Is Through The Normal Equation Using Matrix Algebra, But I Have Never Seen A Nice Closed Form Solution For Each $\Hat{\Beta}_I$.
Web i have tried different methodology for linear regression i.e closed form ols (ordinary least squares), lr (linear regression), hr (huber regression),. Web closed form solution for linear regression. (11) unlike ols, the matrix inversion is always valid for λ > 0. Web in this case, the naive evaluation of the analytic solution would be infeasible, while some variants of stochastic/adaptive gradient descent would converge to the.
This Makes It A Useful Starting Point For Understanding Many Other Statistical Learning.
Web i wonder if you all know if backend of sklearn's linearregression module uses something different to calculate the optimal beta coefficients. Web viewed 648 times. The nonlinear problem is usually solved by iterative refinement; 3 lasso regression lasso stands for “least absolute shrinkage.
Β = ( X ⊤ X) −.
We have learned that the closed form solution: Web solving the optimization problem using two di erent strategies: (xt ∗ x)−1 ∗xt ∗y =w ( x t ∗ x) − 1 ∗ x t ∗ y → = w →. Y = x β + ϵ.
For Linear Regression With X The N ∗.
Normally a multiple linear regression is unconstrained. Web it works only for linear regression and not any other algorithm. Newton’s method to find square root, inverse. These two strategies are how we will derive.